myhalfsea's Blog
Happy coding
偶的项目错误记载
2011/04/05 关于struts2的错误
我用struts2和hibernate3、dwr来做毕业设计,原以为周多一周局可以搞定,但有两个错误却让我检查了3天。
1、看代码
public class Login extends ActionSupport {
Login(){
System.out.println("xxxxxxxxxxxx");
}
public String pointLogin(){
HttpServletRequest request=ServletActionContext.getRequest();
String userid = request.getParameter("userid");
String password = request.getParameter("password");
System.out.println(userid+": " + password);
return "success";
}
}
这是我用于测试登录页是否能正确跳转的代码,你发现那里错了吗?
一般情况下,他是没错的,但是在struts2框架下,该项目根本无法启动!为什么?因为构造方法是默认权限(default),且看default权限的描述:默认权限(default)类,数据成员,构造方法,方法成员,都能够使用默认权限,即不写任何关键字。默认权限即同包权限,同包权限的元素只能在定义它们的类中,以及同包的类中被调用。 不仅仅default不可以,protected也不可以。所以,如果你一定要写构造方法,那么请加上public。
2、先看看struts2.xml配置文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.1//EN"
"http://struts.apache.org/dtds/struts-2.1.dtd">
<struts>
<constant name="struts.i18n.encoding" value="UTF-8"></constant>
<constant name="struts.locale" value="zh_CN"></constant>
<package name="count" namespace="/count" extends="struts-default">
<interceptors>
<interceptor name="userInterceptor" class="com.common.UserInterceptor"></interceptor>
<interceptor-stack name="myInstance">
<interceptor-ref name="defaultStack"></interceptor-ref>
<interceptor-ref name="userInterceptor"></interceptor-ref>
</interceptor-stack>
</interceptors>
<default-interceptor-ref name="myInstance"></default-interceptor-ref>
<global-results>
<result name="error">login.jsp</result>
</global-results>
<action name="login" class="com.action.Login" method="pointLogin">
<result name="success">WEB-INF/jsp/content.jsp</result>
<result name="error">login.jsp</result>
</action>
</package>
</struts>
这段代码有错吗?没有!我也是这么觉得的。但是出现一个问题:在我点击“登录”按钮后,页面跳转了,Login()构造方法也也执行了,但是却是空白页面,查看源代码也是神马也木有!我找哇找,重写了4个project,最后我把struts.xml中关于拦截器的代码注释了,然后就好了……啊啊啊……啊啊……啊……………………我表示,我的拦截器里面神马也没写,我就是先配置好,放在那儿也不行哇!!!他就那样给我全过滤了!血的教训……………………
好文章地址收集
java 内部类 http://myhalfsea.is-programmer.com/admin/drafts/25747/edit
abstract class和interface的区别:http://fzfx88.iteye.com/blog/115393
《Thinking in java》阅读笔记(7)-并发
线程是全新的,理解线程,对程序员的境界可谓是很大的一个飞跃。
我遇到了问题,先看一个正确的程序:
public class Fibonacci implements Runnable{
private int n;
private long[] a = new long[100];
Fibonacci(){}
public Fibonacci( int n ){
this.n = n;
a[0] = 1;
a[1] = 1;
for( int i = 2; i < a.length; i++ )
a[i] = a[i-1] + a[i-2];
}
@Override
public void run() {
for( int i = 0; i < n; i++ ) {
System.out.println( n + "列: "+ a[i]);
Thread.yield();
}
}
}
public class MainThread {
public static void main(String[] args) {
for( int i = 1; i <= 3; i++ ){
Thread d = new Thread( new Fibonacci(3*i)); // 1
d.start(); // 2
}
}
}
输出为顺序混乱的结果,正确的结果。但是,若将1、2换成:Fibonacci f = new Fibonacci(3*i); f.run(); 则输出结果是顺序的;我知道是因为Thread.yield()的原因,但是,我应该怎么改才正确呢?
Executor:
java.util.concurrent 包中的执行器Executor 可以为你管理Thread 对象,从而简化并发编程。Executor在客户端和任务执行之间提供了间接层。与客户端直接执行代码不同,这个Executor将执行任务。Executor 允许你管理异步任务的执行,而无须显示的管理线程的生命周期。是Java Se5/6中启动任务的优选方法。
将main()改为:
ExecutorService sec = Executors.newCachedThreadPool();
for( int i = 1; i <= 3; i++ )
sec.execute( new Fibonacci(i*3) );
sec.shutdown(); //执行完后,尽快退出,防止新的任务提交给这个executor。
可见,没有重复的创建Thread.
《Thinking in java》阅读笔记(6)-I/O
之前对I/O的理解总是处于混沌状态,所以用的时候总是要查资料,但是总是记不住。下面根据我的思路,一步一步的深入理解:
I/O系统可以分为两大类:InputStream/OutputStream、Reader/Writer:

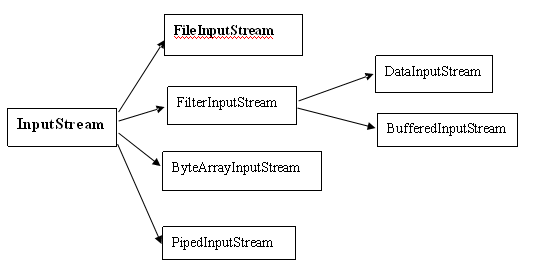
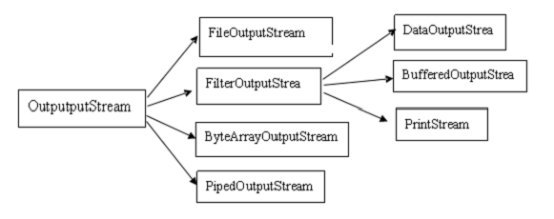
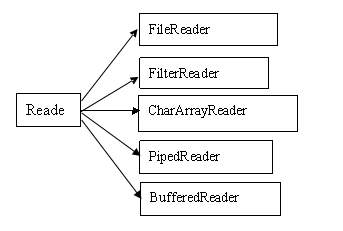
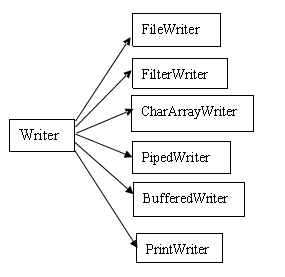
Reader/Writer存在的原因:
1、老的I/O系统(即InputStream/OutputStream)仅支持8位字节流,不能很好的处理16位Unicode,而Unicode用于国际化。
2、新的速度比旧类更快。 所以应当尽量使用Reader/Writer。
基本输入:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.ListIterator;
public class TestSort{
public static String read( String filename) throws IOException{
BufferedReader in = new BufferedReader(new FileReader(filename));
List<String> list = new ArrayList<String>();
String s = "aa";
StringBuilder sb = new StringBuilder();
while( ( s = in.readLine()) != null ){
list.add(s);
}
ListIterator<String> it = list.listIterator(list.size()-1);
while( it.hasPrevious() ){
sb.append("\n"+it.previous());
}
in.close();
return sb.toString();
}
public static void main(String[] args) throws IOException {
System.out.println(TestSort.read("f://java/TestSort.java"));
}
}
输出即为将整个程序倒着输出。
比较ByteArrayInputStream(允许将内存的缓冲区作为InputStream使用):将main()方法改为如下(输出不变):
public static void main(String[] args) throws IOException {
TestSort t = new TestSort();
try{
DataInputStream in = new DataInputStream( new ByteArrayInputStream(
TestSort.read("f://java/TestSort.java").getBytes()));
while( true ) System.out.print((char)in.readByte());
}catch(EOFException e){
System.out.println();
}
}
注意:以上用捕获异常来检测输入的结束,但是,使用异常进行流控制,被认为是对异常特性的错误使用。正确的方法是:
public static void main(String[] args) throws IOException {
TestSort t = new TestSort();
DataInputStream in = new DataInputStream(
new ByteArrayInputStream(
TestSort.read("f://java/TestSort.java").getBytes()));
while( in.available() != 0 )
System.out.print((char)in.readByte());
}
但是avialable(方法)对于不同的类型的流,应该谨慎使用。
基本的文件输出:
FileWriter对象向文件写入数据。通常用BufferedWriter将其包装起来用于缓冲输出(缓冲能显著增加性能),也可以不用包装
public static void main(String[] args) throws IOException {
String file = "f://java/test.java";
PrintWriter pw = new PrintWriter(file);
// PrintWriter pw = new PrintWriter(new BufferedWriter(new FileWriter(file)));
BufferedReader in = new BufferedReader(new FileReader("f://java/TestSort.java"));
String s;
while( (s = in.readLine() ) != null )
pw.write(s+"\n");
pw.close();
System.out.println(TestSort.read(file));
}
用以下方式,可以将信息存储在文件中,读出的结果正确。
但是有两个问题,1、打开文件却是乱码,怎么解决?待解决……………………………………………………………
2、非得用in.readXXX()的形式吗,如果我不知道类型呢? 答:保险起见,写入文件是全用UTF形式,读的时候也全用UTF。
public static void main(String[] args) throws IOException {
DataOutputStream out = new DataOutputStream(
new BufferedOutputStream(new FileOutputStream("f://java/test.txt")));
out.writeUTF("面朝大海,春暖花开\nWhat's you name?");
out.writeInt(21313);
out.close();
DataInputStream in = new DataInputStream(
new BufferedInputStream(new FileInputStream("f://java/test.txt")));
while( in.available() != 0 )
System.out.println(in.readUTF());
in.close();
}
输出:
面朝大海,春暖花开
What's you name?
201314


《Thinking in java》阅读笔记(5)—String
1、String 的方法有哪些?
2、java.util.Formatter:此类提供了对布局对齐和排列的支持,以及对数值、字符串和日期/时间数据的常规格式和特定于语言环境的输出的支持,例如:
Test t = new Test();
StringBuffer s = new StringBuffer();
Formatter f = new Formatter(s, Locale.US);
f.format("%-15s %5s %10s\n", "名字", "age", "sex");
System.out.println(s);
输出:名字 age sex
以上程序结果等同于:
String s = String.format("%-15s %5s %10s\n", "名字", "age", "sex");
System.out.println(s);
在String.format()内部,也需要创建一个Formatter,但显然,我们可以偷懒。
《Thinking in java》阅读笔记4—集合
集合不等同于容器,只是容器中的一部分。
集合分为3大类:List、Map、Set。其中每一种之下又有不同的实现。比如常见的,List下有ArrayList、LinkedList、Vector,Map下有HashMap、TreeMap、HashTable,Set下有HashSet, TreeSet等等。
ArrayList:
ArrayList其实就是用数组保存数据,加入数据时,如果数组已满,就新建一个数组,其长度为原来的2倍。
平时我们在遍历ArrayList时,喜欢用迭代器Iteretor,向后移动。还有一个值得注意的迭代器ListIterator<E>,之前居然完全不知道有这个东东,其只能用于List,可以向后、向前移动。还可以改变当前只想的值。如下例子:
public class Test{
public static void main(String[] args) {
Test t = new Test();
List list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
ListIterator<Integer> it = list.listIterator();
while( it.hasNext() ){
Integer i = it.next();
System.out.println(it.nextIndex()+":"+ i);
if( i.equals(2)) it.set(22);
}
Iterator it2 = list.iterator();
while( it2.hasNext() ){
System.out.println(it2.next());
}
}
}
输出:
1:1
2:2
3:3
1
22
3
Vector:
Vector中的数据不允许重复,其容量也是可变的,Vector 的大小可以根据需要增大或缩小,以适应创建 Vector 后进行添加或移除项的操作。 Vector是线程安全的,在不用考虑现成安全的情况下,通常用ArrayList
关于HashTable 和 HashMap的区别:
1、HashTable中,键或值必须是非null对象
2、HashTable是同步的,是线程安全的;若果使用:Map m = Collections.synchronizedMap(new HashMap(...)),HashMap才是线程安全的,如果直接是Map m = new HashMap(...),则它必须 保持外部同步。
Set:
set内部元素不能重复,无次序,set实际上是一颗红黑树,最常用的set是hashSet,用hashSet存放对象时,该对象必须重写equals()方法,同事也需要实现hashCode()方法,不然就达不到set的目的(即判断重复)。举例说明:
package test;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class TestSort{
public static void main(String[] args){
Set<Student> hs=new HashSet<Student>();
hs.add(new Student("rose",2));
hs.add(new Student("Jack",5));
hs.add(new Student("Lily",22));
hs.add(new Student("Jack",5));
Iterator<Student> it=hs.iterator();
while(it.hasNext()){
System.out.print(it.next().name+" ");
}
}
}
class Student{
int age;
String name;
public Student(String name,int age){
this.name=name;
this.age=age;
}
public int hashCode(){ //返回一个能够唯一标识一个对象的值
return age+name.hashCode();
}
public boolean equals(Object o){// 这两个方法一定要同时实现
Student st=(Student)o;
return age==st.age && name.equals(st.name);
}
}
输出:Lily Jack rose
优先队列:如果队列里面存放的是对象的引用,那么该对象必须实现Comparable,重写compareTo()方法。例如:
import java.util.PriorityQueue;
public class TestSort extends PriorityQueue<TestSort.Point>{
static class Point implements Comparable<Point>{ //实现Comparable接口
private Integer a;
Point(){}
Point( Integer a){
this.a = a;
}
public Integer getA() {
return a;
}
public void setA(Integer a) {
this.a = a;
}
@Override
public int compareTo(Point o) { //重写compareTo方法
if( a > o.a ) return 1;
if( a == o.a ) return 0;
return -1;
}
}
public static void main(String[] args) {
TestSort t = new TestSort();
t.add(new Point(10));
t.add(new Point(21));
t.add(new Point(3));
t.add(new Point(55));
while( !t.isEmpty() ){
System.out.print(t.remove().a+" ");
}
}
}
输出:3 10 21 55
《Thinking in java》阅读笔记(3)-复用类、final
java中类的复用分为3种:组合、继承、代理
1、组合:在新的类中产生现有类的对象,因为现有类的对象是新类的组成部分,所以被称为组合。
2、继承 继承就不用多说了
3、代理,java并没有对代理产生实际的支持,但很多工具中支持。
final关键字:
1、final数据:对于基本类型,数值不能改变;对于对象引用,引用不变,一旦一个引用指向一个对象,就不能将其指向另一个。
空白final:还是举例比较实在:
public class Test{
private final int i = 0; //直接初始化
private final int j; //如果此时为初始化,在每个不同的构造器中必须初始化,
Test(){
j = 1; // 构造器初始化
}
Test( int x ){
j = x; // 构造器初始化
// i = 2; 不能改变i的值
}
public void p(){
// j = 2; 非构造器中,不能改变其值
System.out.println("j:"+j);
}
}
2、final参数,如:
public void p(final int a){
System.out.println("a:"+a);
// a = 10; 不能更改值
}
3、final方法:很容易想到,final方法是不能被重写的
4、final类
final类是不可以被继承中。里面所以方法都隐式的指定为final。
小提示:Vector里面的数据不能存放基本类型,基本类型需要传换成包装类。
《Thikning in java》阅读笔记(3)-权限
java 中,对于某些严谨的程序,读前线的控制应该引起足够的重视,以前在写代码的时候,追求方便和速度,将几乎所有的方法都设置为public,在<Thinking in java>中,将前端程序员与类开发者分开,我到现在还不明白为什么要这样做。如果单单是写一个工具类型的软件,可以称为“类开发者”,但实际上,在中国,除了大型的软件公司,自己包装一下框架外,有多少这样的类开发者呢?
扯远了……
对于public、protected、private的理解:
public不用说,全局有效的。
private的属性与方法,只能在类定义体里面可以访问。
protected呢? 相同包内的其他类、所有继承此类的子类可以访问protected的元素。
《Thinking in java》阅读笔记(2)-数组
先看一段程序:
public class Test {
public static void main(String[] args) {
int[] a1 = {1, 2, 3};
int[] a2 = a1;
for( int i = 0; i < a1.length; i++ ){
a2[i] += 1;
System.out.println("a["+i+"] = "+a1[i]);
}
}
}
输出为:
a[0] = 2
a[1] = 3
a[2] = 4
程序中a2只是a1的别名,他们指向相同的空间。所有a2的改变,在a1中叶体现。
所有数组有一个属性:length,数组下表介于0到length-1之间,超出后,将抛出运行时异常,但在c/c++中,将默默接受,允许方位其内存,最终导致很难检查的错误。
刚看到一段神奇的代码,在之前,从来没见过此种写法:
public class Test {
public void f(Character...a){
System.out.println("first");
for( Character c: a){
System.out.println("a---:"+c);
}
}
public void f(Integer...a){
System.out.println("second");
for( Integer c: a){
System.out.println("b===:"+c);
}
}
public static void main(String[] args) {
Test t = new Test();
t.f('a','b', 'c');
t.f(1, 2, 3, 4);
}
}
输出:
first
a---:a
a---:b
a---:c
second
b===:1
b===:2
b===:3
b===:4
其实方法定义时,只是将参数列表装换为数组,如果列表中没有任何元素,则转换后的数组长度为0。
疑问:Character也是数据类型? 等同于 char ?
关于Arrays的用法:
Arrays的方法只有几个,Arrays.asList(), Arrays.fill(...),Arrays.binarySearch(...), Arrays.sort(...), Arrays.copyOf(...), Arrays.equeals(...)等等
关于sort(T[] a, Comparator<? super T> c)的使用举例:其实与c差不多
public class TestSort{
public static void main(String[] args) {
TestSort t = new TestSort();
Point[] p = new Point[]{new Point(1, "rose"),new Point( 15, "jack"),new Point( 3, "lily"),new Point( 7, "jane")};
Arrays.sort(p,Comptor.getComparator() );
for( int i = 0; i < p.length; i++ ){
System.out.println(p[i].getA()+":"+p[i].getB());
}
}
}
class Comptor{
public static Comparator getComparator() {
return new Comparator() {
public int compare(Object o1, Object o2) {
if( o1 instanceof Point && o2 instanceof Point ){
return comp((Point)o1, (Point)o2);
}
else return 0;
}
};
}
public static int comp( Point p1, Point p2 ){
if( p1.getA() > p2.getA() ) return 1;
if( p1.getA() == p2.getA() ){
if( p1.getB().charAt(0) >= p2.getB().charAt(0) ) return 1;
else return 0;
}
else return 0;
}
}
class Point{
private int a;
private String b;
Point(){}
Point( int a, String b ){
this.a = a;
this.b = b;
}
public void setA( int a ){
this.a = a;
}
public void setB( String b ){
this.b = b;
}
public int getA(){
return a;
}
public String getB(){
return b;
}
}
输出:
1:rose
3:lily
7:jane
15:jack
《Thinking in java》阅读笔记(1)-static
应聘的时候,老是会有关于static的考题。看了前几章我才发现,以前自己都是死记硬背的……根本没有理解所以然。
理解static,首先要理解一个对象的创建过程。
引用<Thinking in java>的话:创建一个对象的过程,假设有一个类就叫做Dog。
1、即使没有显式的使用关键字,构造器实际上是静态方法。因此,在首次创建Dog对象或者调用Dog的静态方法/域时,java解释器必须查找Dog.Class的路径
2、载入Dog.Class(浙江创建一个Dog对象),有关静态初始化 的动作将执行,因此,静态方法/域只在第一次加载时执行。
3、当用 new Dog()创建一个Dog对象时,首先在堆栈上为该对象创建足够的存储空间
4、这个存储空间将清零,所有基本类型的数据将赋予默认值,引用将赋值为null。
5、执行所有定义初始化的动作
6、执行构造器。
在了解了对象创建过程后,理解static的原理就要简单得多。如下例子:
public class Test {
public static void main(String[] args) {
System.out.println("come into inside");
Cups cups1 = new Cups();
cups1.cup1.p();
Cups cups2 = new Cups();
}
}
class Cup{
Cup( int k ){
System.out.println("第"+k+"个");
}
public void p(){
System.out.println("===================");
}
}
class Cups{
static Cup cup1, cup2;
static{
cup1 = new Cup(1);
cup2 = new Cup(2);
}
Cups(){
System.out.println("cups");
}
}
输出为:
第1个
第2个
cups
===================
cups
由此可见static代码块只执行了一次 ,并且是在构造器执行之前,类加载时就执行的。
*************注意以下两个关于继承和static的程序:
程序1:
public class Test{
public static void main(String[] args) {
Test t = new Test();
Animal a = new Dog();
System.out.println(a.getName());
}
}
class Animal{
Animal(){}
public static String getName(){ // -----1----
return "animal";
}
}
class Dog extends Animal{
Dog(){}
public static String getName(){ //----2----
return "dog";
}
}
输出是: animal
如果将两个getName()的方法的static 都去掉,则输出为:dog 此时是重写方法
可见,static修饰的方法是不具有多态性。但是,如果只是将1或者2中的static去掉,是不行的。
Butterfly Theme | Design: HRS Hersteller of mobile Hundeschule.